Perceive
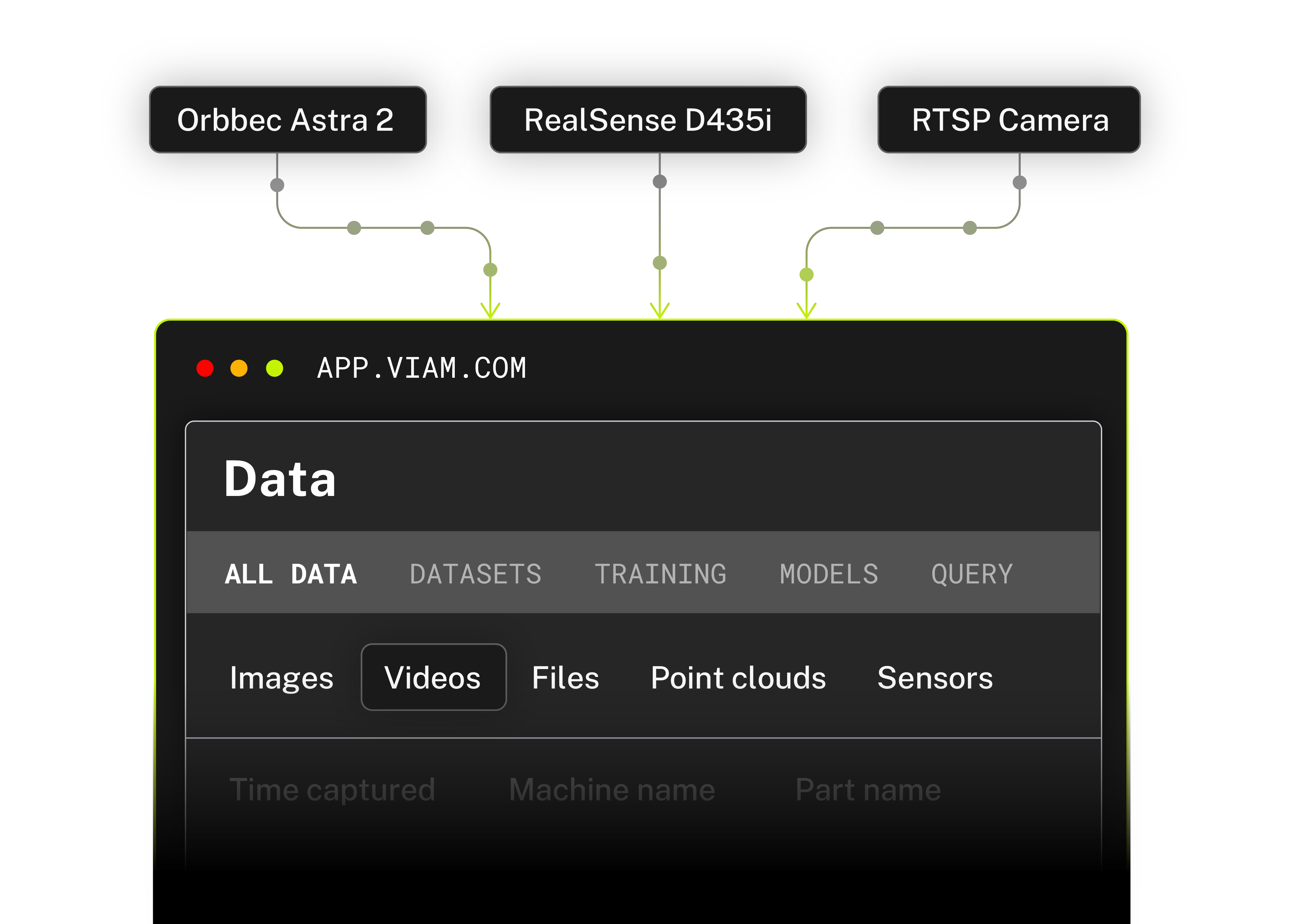
Capture the data that matters. Skip the pipeline work.
Declare what you want to capture in a JSON config. Viam handles ingestion, edge buffering, and cloud sync, no custom pipeline required.
- Data queues locally during outages and syncs when connectivity returns
- Intelligent triggers from low-confidence detections or sensor thresholds
- Standardized streams across any camera or sensor
- Swap hardware without rewriting data logic
evolve
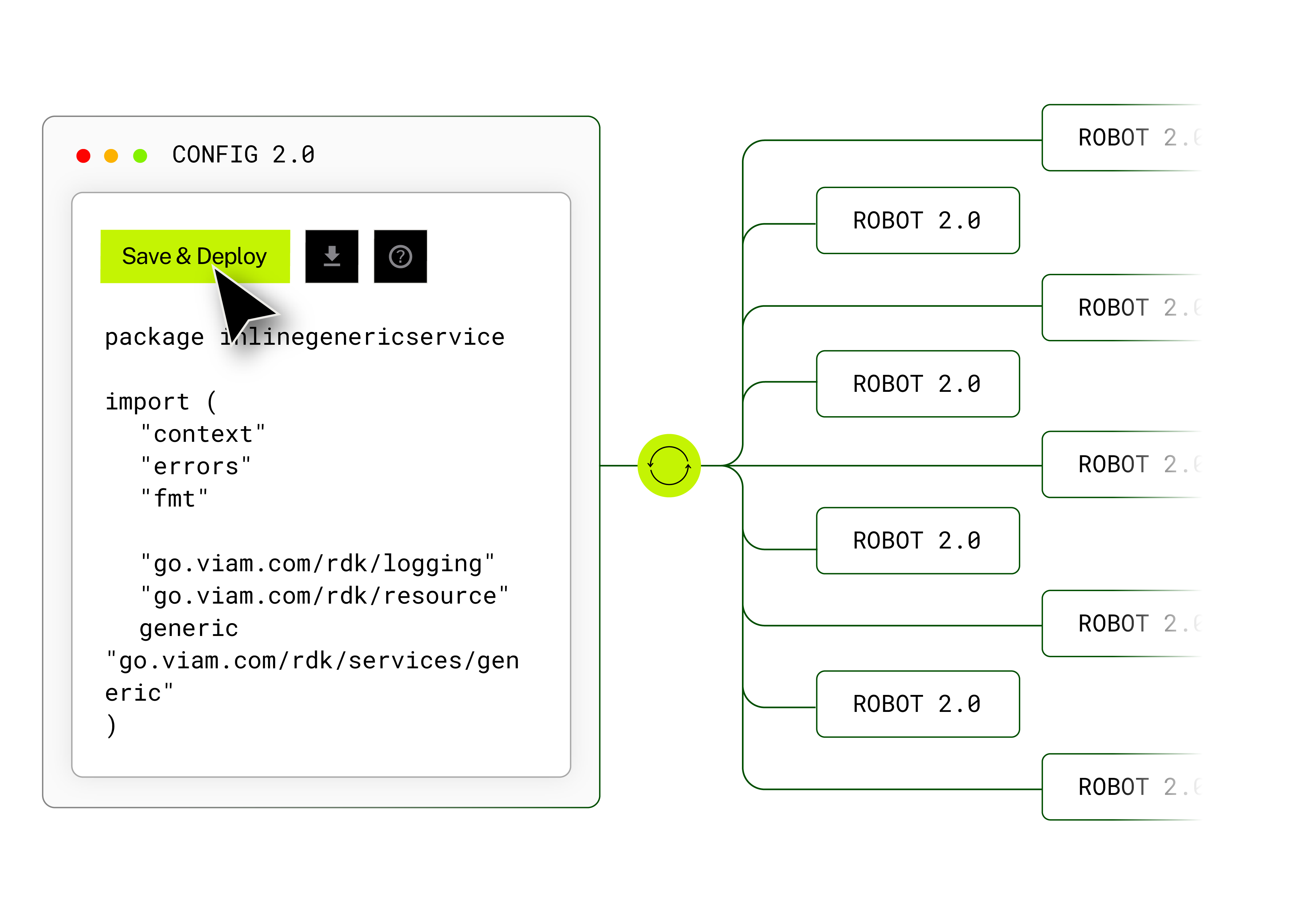
Move from raw data to trained models faster.
Annotation and training live inside the same platform as your fleet. No exports, no third-party handoffs, no broken handoff between capture and training.
- Label data in-platform directly from captured fleet data
- Support for TensorFlow, PyTorch, and ONNX models
- Native training inside the Viam platform
- Models stored and versioned in the Registry as managed assets
Act
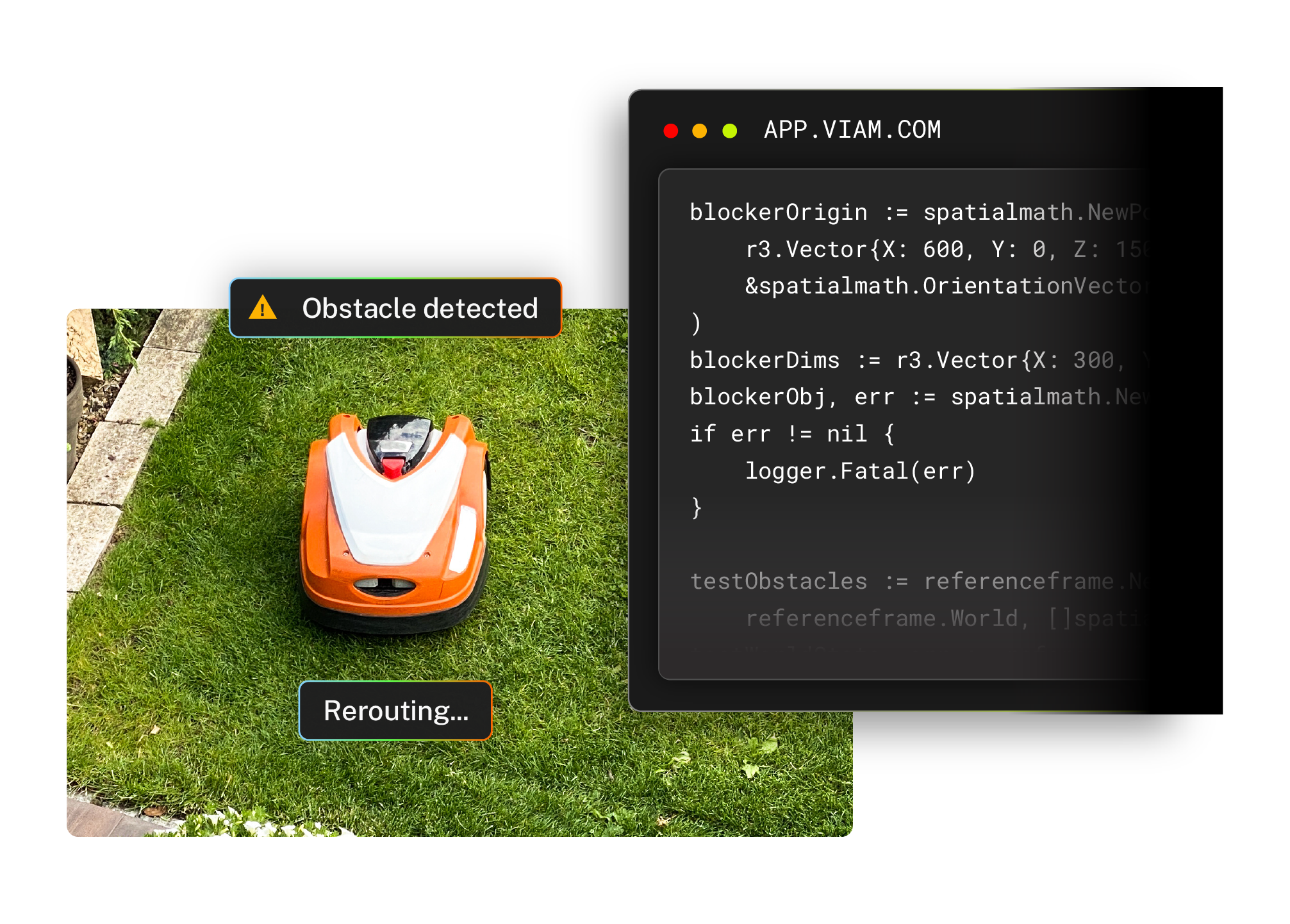
Run inference at the edge. React in real time.
Viam’s ML Model Service runs natively on your hardware. If a machine detects a hazard, it reacts without needing a server.
- Local-first architecture for on-device inference without a network connection
- Hardware acceleration on GPU and TPU to prevent application bottlenecks
- Model outputs called through the same SDKs used for motion control
- Perception and action integrated into a single stack